Comparative analysis of ChatGPT 3.5 and ChatGPT 4 obstetric and gynecological knowledge – Nature
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
Advertisement
Scientific Reports volume 15, Article number: 21133 (2025)
224
1
Metrics details
Generative Pretrained Transformer (GPT) is one of the most ubiquitous large language models (LLMs), employing artificial intelligence (AI) to generate human-like language. Although the use of ChatGPT has been evaluated in different medical specialties, sufficient evidence in the field of obstetrics and gynecology is still lacking. The aim of our study was to analyze the knowledge of the two latest generations of ChatGPT (ChatGPT-3.5 and ChatGPT-4) in the area of obstetrics and gynecology, and thereby to assess their potential applicability in clinical practice. We submitted 352 single-best-answer questions from the Polish Specialty Certificate Examinations in Obstetrics and Gynecology to ChatGPT-3.5 and ChatGPT-4, in both Polish and English. The models’ accuracy was evaluated, and performance was analyzed based on question difficulty and language. Statistical analyses were conducted using the Mann–Whitney U test and the chi-square test. The results of the study indicate that both LLMs demonstrate satisfactory knowledge in the analyzed specialties. Nonetheless, we observed a significant superiority of ChatGPT-4 over its predecessor regarding the accuracy of answers. The correctness of answers of both models was associated with the difficulty index of questions. In addition, based on our analysis, ChatGPT should be used in English for optimal performance.
Generative Pretrained Transformer (GPT) is one of the most ubiquitous large language models (LLM), employing artificial intelligence (AI) to generate human-like language1. The latest enhancements in AI have led to the development of promising technological advancements, such as the ChatGPT1. To date, LLMs have demonstrated significant applicability across numerous fields, including healthcare, business, education, and research2. In addition, this AI-based technology is continuously improving as LLMs are constantly being trained based on large volumes of text data from the internet, which employs a neural network architecture called “Transformer”3.
The first LLM, GPT-1, was released in 2018 and included 117 million pre-trained parameters. Its successor, GPT-2, comprised 1.5 billion parameters and was introduced in late 2019. The currently available versions, ChatGPT-3.5 and ChatGPT-4, were launched in November 2022 and March 2023, respectively4. ChatGPT became the fastest-growing application in history, having gained 1 million users in 5 days and 100 million users in just 2 months after its introduction. The first ChatGPT release was based on the 3.5 version of the GPT model5. Developed in the following year, ChatGPT-4 is believed to be superior to its predecessor and is currently available only under a paid subscription. OpenAI, the company behind ChatGPT, illustrates this disparity by claiming that ChatGPT-4 is capable of passing a simulated bar exam with a score fluctuating around the top 10% of candidates, whereas ChatGPT-3.5 – the bottom 10%6. This can be attributed to the fact that ChatGPT-4 has a larger context window compared to ChatGPT-3.5, meaning it can process and retain more information within a single conversation. This leads to better continuity, making it useful for in-depth discussions, summarization, and long-form text generation. Moreover, it has been fine-tuned to follow stricter safety and ethical guidelines, making it more reliable for professional and academic use6.
Nowadays, ChatGPT is a cutting-edge chatbot whose accuracy is constantly improving; therefore, significant attention has been drawn to its potential applicability in aiding physicians’ decision-making processes7,8. The growing interest in ChatGPT has resulted in a substantial number of publications evaluating the use of LLMs in medicine, including both education and clinical management9. Numerous studies have investigated the potential of ChatGPT usage in different medical specialties10,11,12. Nonetheless, sufficient evidence regarding ChatGPT’s knowledge of obstetrics and gynecology is still lacking, as this field has not been evaluated thoroughly. Existing studies that do address this area often rely on small or unofficial datasets, limiting their clinical applicability. Moreover, the impact of language on ChatGPT’s performance remains underexplored as most LLMs are predominantly trained on English corpora.
The purpose of presented study was to examine the capacity of ChatGPT-3.5 and ChatGPT-4 to support physicians’ decision-making in daily medical practice and, as a result, to enhance their clinical performance. ChatGPT’s knowledge was evaluated based on the correctness of answering questions from the Polish Specialty Certificate Examination (SCE) in Obstetrics and Gynecology. In addition, we aimed to analyze the pace of the development of the AI language models by comparing the performance of the two latest generations of ChatGPT.
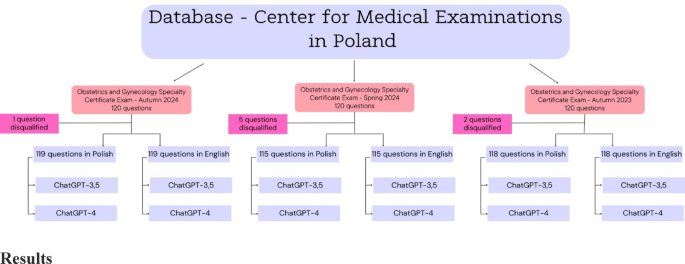
In this comparative cross-sectional study, multiple-choice format questions with five possible answers, incorporating a single-best-answer format, were submitted in December 2024 to ChatGPT, using both GPT-3.5 and GPT-4.0 language models (OpenAI, San Francisco, United States). The questions used for the assessment of ChatGPT’s knowledge were derived from the three latest SCE in Obstetrics and Gynecology (Autumn 2023, Spring and Autumn 2024) organized by the Center for Medical Examinations (CEM) in Poland, the passing of which is required to obtain the title of specialist in obstetrics and gynecology. SCEs were selected as they provide comprehensive questions based on the guidelines of the Polish Society of Obstetricians and Gynecologists, as well as on textbooks recommended by the National Consultant in Obstetrics and Gynecology. Each test initially comprised 120 questions, however, there were single questions that were disqualified in each of the sessions due to inconsistency with the current knowledge. As the exams were originally conducted in Polish, all questions were translated into English by a certified medical translator with expertise in obstetrics and gynecology. This approach ensured that medical terminology, contextual meaning, and clinical nuances were preserved. Furthermore, it aided to minimize potential discrepancies between the original and translated versions that could affect model interpretation or performance. The summary of the research strategy is shown in Fig. 1. Ethical approval and informed consent were not required since the study did not involve human participants.
Each consecutive question was entered in a separate chat room. ChatGPT discussed the topic of the submitted questions in almost every case, which justified the selected answer. If ChatGPT did not respond with a definite answer, investigators resubmitted the question in a new chat, adding the prompt “Choose the best option” after the question mark. In total, both ChatGPT-3.5 and ChatGPT-4 were asked 352 questions in Polish and 352 questions in English. Of importance, having received an incorrect answer, the investigators did not provide ChatGPT with the correct one. This approach was adopted to avoid influencing subsequent outputs and to ensure the integrity and reproducibility of the performance evaluation.
Following the above-mentioned analysis, investigators assessed whether the difficulty of questions has an impact on the performance of ChatGPT. The percentage of physicians who selected a particular answer in conjunction with the difficulty index (DI) of each question has been made publicly available by the CEM. The mathematical formula used for the DI calculation was: DI = (Ns + Ni)/2n, where ‘n’ is the total number of examinees from each of two extreme groups (defined as: 27% of the test takers with the best and the worst results over the entire test, respectively); ‘Ns’ is the number of correct answers to the question in the group with the best results; and ‘Ni’ is the number of correct answers to the question in the group with the worst results. Calculated DI includes values ranging from 0 (for very difficult questions) to 1 (for very easy questions).
For comparisons between continuous and categorical variables, the Mann–Whitney U test and the chi-square test were applied, respectively. All data were expressed as median and interquartile range [IQR], or as frequency (%). A p-value < 0.05 was considered statistically significant. All data were entered into an electronic database using Microsoft Office Excel 365 (Microsoft Corp., Redmond, WA) and analyzed with the IBM SPSS Statistics (version 30.0; IBM, Armonk, New York).
Summary of research strategy.
ChatGPT-3.5 and ChatGPT-4 obtained 44.5% and 76.5% of correct answers in the Autumn 2024 session, respectively. In Spring 2024, the percentages of correct answers were 66.0% and 83.5%, and in Autumn 2023, 61.0% and 83.0%, respectively. ChatGPT-4 outperformed the older version in every test, and all the differences were statistically significant (each p < 0.001, Table 1).
In English, ChatGPT-3.5 and ChatGPT-4 scored 63.0% and 83.2% in the Autumn 2024 session, respectively. In Spring 2024, the analyzed LLMs scored 73.9% and 89.6%, whereas, in Autumn 2023, 66.9% and 87.3%, respectively. In every test, ChatGPT-4 achieved better outcomes than ChatGPT-3.5 and all differences were statistically significant (each p < 0.001, Table 1).
In the comparison of results in Polish vs. English, ChatGPT-3.5 achieved 44.5% vs. 63.0%, 66.0% vs. 73.9%, and 61.0% vs. 66.9% correct answers for Autumn 2024, Spring 2024 and Autumn 2023 sessions, respectively. Statistically significant differences were found for each test (each p < 0.001, Table 2).
When compared Polish vs. English, ChatGPT-4 obtained 76.5% vs. 83.2%, 83.5% vs. 89.6% and 83.0% vs. 87.3% corrects answers in the Autumn 2024, Spring 2024 and Autumn 2023 sessions, respectively. Again, all of the differences were statistically significant (each p < 0.001, Table 2).
The comparative analysis revealed that questions answered incorrectly by ChatGPT-3.5 and ChatGPT-4 in Polish and English were characterized by lower median DI values for all tests compared to questions answered correctly. The differences were statistically significant except for Spring 2024 session in both languages for both versions (Table 3).
This study aimed to analyze and compare the knowledge in obstetrics and gynecology of the two latest versions of ChatGPT by measuring the correctness of answers to highly specific questions in the field. We have addressed existing gaps in the current literature by analyzing ChatGPT-3.5 and ChatGPT-4 performance on over 350 validated questions from the three recent sessions of the Polish SCE in Obstetrics and Gynecology, both in Polish and English, providing one of the most comprehensive and domain-specific evaluations of LLMs accuracy to date. Our analysis revealed that ChatGPT-4 would pass every SCE test, where the pass rate is 60%, whereas the older version would fail the Autumn 2024 exam. Moreover, we found statistically significant differences between the two versions, namely ChatGPT-4 achieved better results in all tests, regardless of the language. The lowest result obtained by ChatGPT-3.5 was 44.5% and the highest – 73.9%. For ChatGPT-4, these values were 76.5% and 89.6%, respectively. A comparison by Meyer et al. revealed a 27% improvement in ChatGPT-4 scores compared to its predecessor on the German Medical Licensing Examination (GMLE)13. Furthermore, ChatGPT-3.5 managed to pass only 1 out of 3 GMLE tests with a mean score of 58%, whereas ChatGPT-4 achieved an average of 85% 13. Of importance, similar observations were made by Rosoł et al., who aimed to compare the performance of both versions on the Polish Medical Final Examination (MFE)14. In that study, ChatGPT-3.5 passed 2 out of 3 tests in Polish and all tests in English, which is consistent with our findings. On the other hand, ChatGPT-4 obtained more points in every single test; however, its results were slightly below medical students’ average14. Interestingly, a comparative analysis based on the performance on the Neurosurgery Board Examinations revealed that higher-order problem-solving and an increased word count were associated with the lower accuracy of the older versions but not of the GPT-4 15. Since ChatGPT-4 was launched only four months after the prior version, the observed distinctions in answer accuracy are substantial.
Our study proved that both versions of the analyzed LLMs performed better in English than in Polish. In each test in English, ChatGPT accuracy was higher compared to Polish and all of the differences were statistically significant. It is well established, that LLMs performance depends on the amount and quality of training data. Moreover, it is believed that ChatGPT is able to communicate in over 100 languages as it learns from text datasets from different countries. Therefore, as English is the most common language for ChatGPT training, its performance is considerably better compared to other languages16. Our findings are consistent with previous publications on the topic3,14,17. Lewandowski et al. reported a higher accuracy of both models in every test in English compared to Polish; however, the differences were not significant, unlike in our analysis17. Likewise, Rosoł et al. reported improved correctness of answers for both models if English was used, except for ChatGPT-4 and questions with a temperature parameter of 0 – in that case, ChatGPT-4 performed with a 1% higher accuracy in Polish compared to English14. Coherent observations concerning other languages have been made in previous publications. For instance, Wang et al. reported considerably greater accuracy in English compared to Chinese on the China National Medical Licensing Examination for both ChatGPT models18. Similar findings regarding ChatGPT performance in Chinese and English were described during the pharmacist licensing examination in Taiwan19. Therefore, based on the results of our study and the existing literature, we suggest that ChatGPT should be used in English for optimal results.
An additional purpose of our study was to analyze the DI of the correct and incorrect answers of both models and thereby to assess whether the difficulty of questions has an impact on the performance of ChatGPT. We found that, in most cases, the questions answered correctly by both LLMs had a significantly higher DI than those answered incorrectly. Therefore, in our analysis, ChatGPT turned out to be more efficient in solving less complex tasks compared to the extremely difficult ones. On the other hand, ChatGPT-3.5 was capable of choosing the correct answer to a question with a DI as low as 0.182 and ChatGPT-4–0.133, which proves that both models can be supportive even in difficult decision-making processes. Interestingly, ChatGPT-3.5 exhibited a marked decline in performance in the Autumn 2024 session, dropping to 44.5% accuracy in Polish and 63.0% in English, hence substantially lower than in the previous two sessions. This finding appears contradictory to the commonly held assumption that LLMs continually improve over time. One possible explanation is that the content or structure of the Autumn 2024 exam may have included more complex or less typical questions, making it disproportionately challenging for earlier versions of ChatGPT. Another possibility is that ChatGPT-3.5, which lacks the architectural advancements and dynamic refinement mechanisms present in ChatGPT-4, may be more sensitive to variation in question framing or clinical subtopics. This underscores the importance of continuous validation of LLMs across changing content domains and periods. To date, numerous publications have investigated the relationship between the DI and the correctness of answers in medical specialties. A study by Siebielec et al. reported that the correct answers by ChatGPT-3.5 were significantly associated with a higher DI20. Noteworthy, the analyzed LLM correctly answered only 37.1% of the questions with a DI up to 0.5, whereas for the questions with a DI above 0.5, the ratio was 63.9% 20. Authors of the study measuring ChatGPT-3.5 performance on the Polish MFE found that the analyzed LLM outperformed physicians in answering questions with a DI below 0.566. However, AI did worse in all other categories of difficulty as compared to physicians21. The same study reported a negative association between the length of the question and the correctness of answers21. Finally, in a study assessing the dermatological knowledge of ChatGPT-3.5 and ChatGPT-4, the authors demonstrated statistically significant differences regarding DI between the correctly and incorrectly answered questions for 5 out of 12 versions of SCE tests17.
The observed performance gap between ChatGPT-3.5 and ChatGPT-4 carries several important clinical implications. ChatGPT-4’s superior accuracy, particularly in English and on moderately difficult or easy questions, suggests that this model could potentially serve as a supportive tool in structured clinical decision-making or medical education in obstetrics and gynecology. However, the observed limitations in addressing complex questions (low DI) and its reduced accuracy in Polish highlight the current boundaries of AI applicability. These findings caution against over-reliance on LLMs in high-stakes clinical scenarios, especially when nuanced judgment, guideline interpretation, or context-specific experience is essential. Until further validated, ChatGPT should be considered a supplementary, not primary, source of guidance in obstetric and gynecological care. Finally, although ChatGPT-3.5 underperformed relative to ChatGPT-4, particularly in complex scenarios and non-English contexts, it may still have selective utility in medical education. Its responses were often helpful in generating broad explanations or clarifying basic concepts, which could support early-stage learners or assist in language-based learning environments. However, given its inconsistency and lower accuracy, ChatGPT-3.5 should be used with caution and only in clearly defined, low-stakes educational scenarios. It should not be employed for advanced clinical decision support or examination preparation without rigorous human oversight.
Our analysis revealed acceptable knowledge of the former version of ChatGPT and a very good proficiency of the more advanced model in the field of obstetrics and gynecology. Although, there has not been sufficient research in the area to date, there is a growing interest in the application of LLMs across various domains of obstetric and gynecological care. For instance, disparities in AI-generated medical recommendations across countries have raised important questions about LLM consistency and equity in global healthcare delivery22. In gynecologic oncology, LLMs have shown potential to assist in clinical decision-making, though the quality and reliability of outputs vary depending on context and case complexity23. Furthermore, emerging research has evaluated the use of AI-based LLMs for tasks such as cardiotocography interpretation, showing promise for real-time clinical applications under supervised conditions24. These findings underscore the importance of continued, domain-specific validation of LLMs, particularly in high-stakes or language-sensitive scenarios, as illustrated by our study. According to the existing literature, in a study by Bachmann et al., ChatGPT-3.5 achieved an overall accuracy of 72.2% and 50.4% in Part One and Part Two of the UK Royal College of Obstetricians and Gynaecologists (MRCOG) exam, respectively25. Interestingly, the analyzed LLM obtained the greatest percentage of points in the “Clinical Management” Sect. (83.3%) and the lowest in the “Biophysics” Sect. (51.4%) in Part One, whereas for Part Two, the extreme sections were “Urogynaecology & Pelvic Floor Problems” (63.0%) and “Management of Labour” (35.6%)25. The Polish SCE exam does not include sections, therefore such analysis could not be performed in our study. Riedel et al. reported that ChatGPT-3.5 outperformed German students in the university obstetrics and gynecology exam (85.6% vs. 83.1%), however, the AI-based model did worse on a medical state exam (70.4% vs. 73.4%)26. Furthermore, the study found that ChatGPT’s performance on the former exam did not differ significantly considering the difficulty level of the question, whereas, in the medical state exam dataset, ChatGPT’s performance on questions defined as “easy“ (1–3 on a 5-point scale) was significantly better26. Our study’s results align with the latter test in the aforementioned study, as we reported significant associations between the correctness of answers by both ChatGPT and the DI. The superiority of ChatGPT over humans in the obstetrics and gynecology exam has been reported by Li et al. who found a better score of the analyzed LLM compared to the average historical human score (77.2% vs. 73.7%)27. The authors concluded that ChatGPT generated factual and contextually relevant structured answers to complex clinical issues with unfamiliar settings quickly; therefore, it outperformed humans in numerous areas27. In another study from Turkey, the authors aimed to assess ChatGPT-4’s knowledge focused specifically on polycystic ovary syndrome28. In the study, full accuracy was reported for the true/false questions28. Noticeable improvements during the 30-day period of the study were noted for open-ended queries, whereas for the multiple-choice questions, a decrease in accuracy was observed28. Surprisingly, ChatGPT-4 demonstrated greater correctness in questions considered “hard” compared to questions of moderate difficulty, and that tendency persisted over the 30-day study period28. Finally, ChatGPT’s knowledge of obstetrics and gynecology has been found to be superior to that of other models, such as HuggingChat; however, the differences were not statistically significant29.
The strengths of presented study include a meticulous comparison of the performance of ChatGPT in three examination sessions prepared by the leading Departments of Obstetrics and Gynecology in Poland. Secondly, our analysis was conducted in two languages – Polish and English, and the use of transparent methodology is another advantage of our study. Finally, it should be noted that, as our study was constrained to the three latest SCE tests, limited prior exposure of ChatGPT to the analyzed questions was ensured. By using real exam questions from a national certifying body in two languages, our study provides novel insights into ChatGPT’s reliability in specialty-specific, high-stakes settings. Study findings not only highlight the superior performance of ChatGPT-4 but also underscore the need for continued language-specific validation before integrating LLMs into clinical decision support systems worldwide. Certain limitations, however, need to be mentioned. Firstly, only two LLMs, both developed by a single manufacturer, were compared in the study. In addition, the analyzed SCE exams did not comprise separate sections; therefore, ChatGTP’s knowledge of more specific fields in obstetrics and gynecology could not be assessed. Another identified weakness of our study is a lack of prompts or input texts entered into the model. Depending on the quality of the prompt, different results can be obtained from the chatbot. However, our aim was to adhere to the official questions from the SCE exams to provide maximum transparency.
ChatGPT, particularly the newest ChatGPT-4 version, demonstrated a high level of obstetric and gynecological knowledge and could hence be implemented in the clinical setting. It should be noted, however, that even though ChatGPT is capable of answering very difficult questions, its accuracy is better when solving less complex problems. ChatGPT-4 significantly outperforms its predecessor; therefore, the newer version should aid physicians in their daily practice. Moreover, both versions should be used in English to provide the best accuracy of answers.
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Open, A. I. Introducing ChatGPT. San Francisco. https://openai.com/blog/chatgpt. Last accessed 22.12.2024.
Fui-Hoon Nah, F., Zheng, R., Cai, J., Siau, K. & Chen, L. Generative AI and chatgpt: Applications, challenges, and AI-human collaboration. J. Inform. Technol. Case Appl. Res. 25, 277–304 (2023).
Article Google Scholar
Taloni, A. et al. Comparative performance of humans versus GPT-4.0 and GPT-3.5 in the self-assessment program of American academy of ophthalmology. Sci. Rep. 13. https://doi.org/10.1038/s41598-023-45837-2 (2023).
Kipp, M. & From GPT-3.5 to GPT-4.o: A leap in ai’s medical exam performance. Information 15, 543 (2024).
Article Google Scholar
Schulman, J., Wolski, F., Dhariwal, P., Radford, A. & Klimov, O. Proximal Policy Optim. Algorithms (2017). http://arxiv.org/abs/1707.06347
OpenAI. GPT-4. https://openai.com/research/gpt-4 (last accessed 22.12.2024).
Huang, Y. et al. Benchmarking ChatGPT-4 on a radiation oncology in-training exam and red journal Gray zone cases: Potentials and challenges for ai-assisted medical education and decision making in radiation oncology. Front. Oncol. 13 https://doi.org/10.3389/fonc.2023.1265024 (2023).
Nakhleh, A., Spitzer, S. & Shehadeh, N. ChatGPT’s response to the diabetes knowledge questionnaire: Implications for diabetes education. Diabetes Technol. Ther. 25, 571–573 (2023).
Article PubMed Google Scholar
Sallam, M. ChatGPT utility in healthcare education, research, and practice: Systematic review on the promising perspectives and valid concerns. Healthc. (Switzerland). 11. https://doi.org/10.3390/healthcare11060887 (2023).
Alhaidry, H. M., Fatani, B., Alrayes, J. O., Almana, A. M. & Alfhaed, N. K. ChatGPT in dentistry: A comprehensive review. Cureus 15. https://doi.org/10.7759/CUREUS.38317 (2023).
Liu, J., Wang, C. & Liu, S. Utility of ChatGPT in clinical practice. J. Med. Internet Res. 25. https://doi.org/10.2196/48568 (2023).
Dave, T., Athaluri, S. A. & Singh, S. ChatGPT in medicine: An overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front. Artif. Intell. 6 https://doi.org/10.3389/FRAI.2023.1169595/FULL (2023).
Meyer, A., Riese, J. & Streichert, T. Comparison of the performance of GPT-3.5 and GPT-4 with that of medical students on the written German medical licensing examination: Observational study. JMIR Med. Educ. 10, e50965 (2024).
Article PubMed PubMed Central Google Scholar
Rosoł, M., Gąsior, J. S., Łaba, J., Korzeniewski, K. & Młyńczak, M. Evaluation of the performance of GPT-3.5 and GPT-4 on the Polish medical final examination. Sci. Rep. 13. https://doi.org/10.1038/s41598-023-46995-z (2023).
Ali, R. et al. Performance of ChatGPT and GPT-4 on neurosurgery written board examinations. medRxiv; 2023.03.25.23287743. (2023).
AI Guider. List of language that ChatGPT supported. https://ai-guider.com/list-of-language-that-chatgpt-supported/ (last accessed 23.12.2024).
Lewandowski, M., Łukowicz, P., Świetlik, D. & Barańska-Rybak, W. ChatGPT-3.5 and ChatGPT-4 dermatological knowledge level based on the specialty certificate examination in dermatology. Clin. Exp. Dermatol. 49, 686–691 (2024).
Article PubMed Google Scholar
Wang, H., Wu, W. Z., Dou, Z., He, L. & Yang, L. Performance and exploration of ChatGPT in medical examination, records and education in Chinese: Pave the way for medical AI. Int. J. Med. Inf. 177, 105173 (2023).
Article Google Scholar
Wang, Y-M., Shen, H-W. & Chen, T-J. Performance of ChatGPT on the pharmacist licensing examination in Taiwan. J. Chin. Med. Assoc. 86 (2023). https://journals.lww.com/jcma/fulltext/2023/07000/performance_of_chatgpt_on_the_pharmacist_licensing.7.aspx
Siebielec, J., Ordak, M., Oskroba, A., Dworakowska, A. & Bujalska-Zadrozny, M. Assessment study of ChatGPT-3.5’s performance on the final Polish medical examination: Accuracy in answering 980 questions. Healthc. (Switzerland). 12 https://doi.org/10.3390/healthcare12161637 (2024).
Suwała, S. et al. ChatGPT-3.5 passes poland’s medical final examination—Is it possible for ChatGPT to become a Doctor in poland?? SAGE Open. Med. 12. https://doi.org/10.1177/20503121241257777 (2024).
Gumilar, K. E. et al. Disparities in medical recommendations from AI-based chatbots across different countries/regions. Sci. Rep. 14, 1–10. (2024).
Gumilar, K. E. et al. Assessment of large Language models (LLMs) in decision-making support for gynecologic oncology. Comput. Struct. Biotechnol. J. 23, 4019–4026 (2024).
Article PubMed PubMed Central Google Scholar
Gumilar, K. E. et al. Artificial intelligence-large Language models (AI-LLMs) for reliable and accurate cardiotocography (CTG) interpretation in obstetric practice. Comput. Struct. Biotechnol. J. 27, 1140–1147 (2025).
Article PubMed PubMed Central Google Scholar
Bachmann, M. et al. Exploring the capabilities of ChatGPT in women’s health: Obstetrics and gynaecology. Npj Women’s Health. 2, 26 (2024).
Article Google Scholar
Riedel, M. et al. ChatGPT’s performance in German OB/GYN exams—paving the way for AI-enhanced medical education and clinical practice. Front. Med. (Lausanne). 10. https://doi.org/10.3389/fmed.2023.1296615 (2023).
Li, S. W. et al. ChatGPT outscored human candidates in a virtual objective structured clinical examination in obstetrics and gynecology. Am. J. Obstet. Gynecol. 229, 172.e1-172.e12. (2023).
Devranoglu, B., Gurbuz, T. & Gokmen, O. ChatGPT’s efficacy in queries regarding polycystic ovary syndrome and treatment strategies for women experiencing infertility. Diagnostics 14. https://doi.org/10.3390/diagnostics14111082 (2024).
Kirshteyn, G., Golan, R. & Chaet, M. Performance of ChatGPT vs. HuggingChat on OB-GYN topics. Cureus https://doi.org/10.7759/cureus.56187 (2024).
Article PubMed PubMed Central Google Scholar
Download references
1st Department of Obstetrics and Gynecology, Medical University of Warsaw, Warsaw, Poland
Franciszek Ługowski, Julia Babińska, Artur Ludwin & Paweł Jan Stanirowski
PubMed Google Scholar
PubMed Google Scholar
PubMed Google Scholar
PubMed Google Scholar
FŁ – conceptualization, data acquisition, original draft writing, statistics; JB – original draft writing, data acquisition; AL – manuscript revision; PJS – conceptualization, manuscript revision, supervision.
Correspondence to Franciszek Ługowski.
The authors declare no competing interests.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
Reprints and permissions
Ługowski, F., Babińska, J., Ludwin, A. et al. Comparative analysis of ChatGPT 3.5 and ChatGPT 4 obstetric and gynecological knowledge. Sci Rep 15, 21133 (2025). https://doi.org/10.1038/s41598-025-08424-1
Download citation
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-08424-1
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
Advertisement
Scientific Reports (Sci Rep)
ISSN 2045-2322 (online)
© 2025 Springer Nature Limited
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.